Intelligent LLM Routing. 80% Less Cost.
A small, fast classifier in front of your LLM stack. Every request hits the advisor first — trivial tasks go to tiny models, complex reasoning goes to frontier models. Same quality, fraction of the cost.

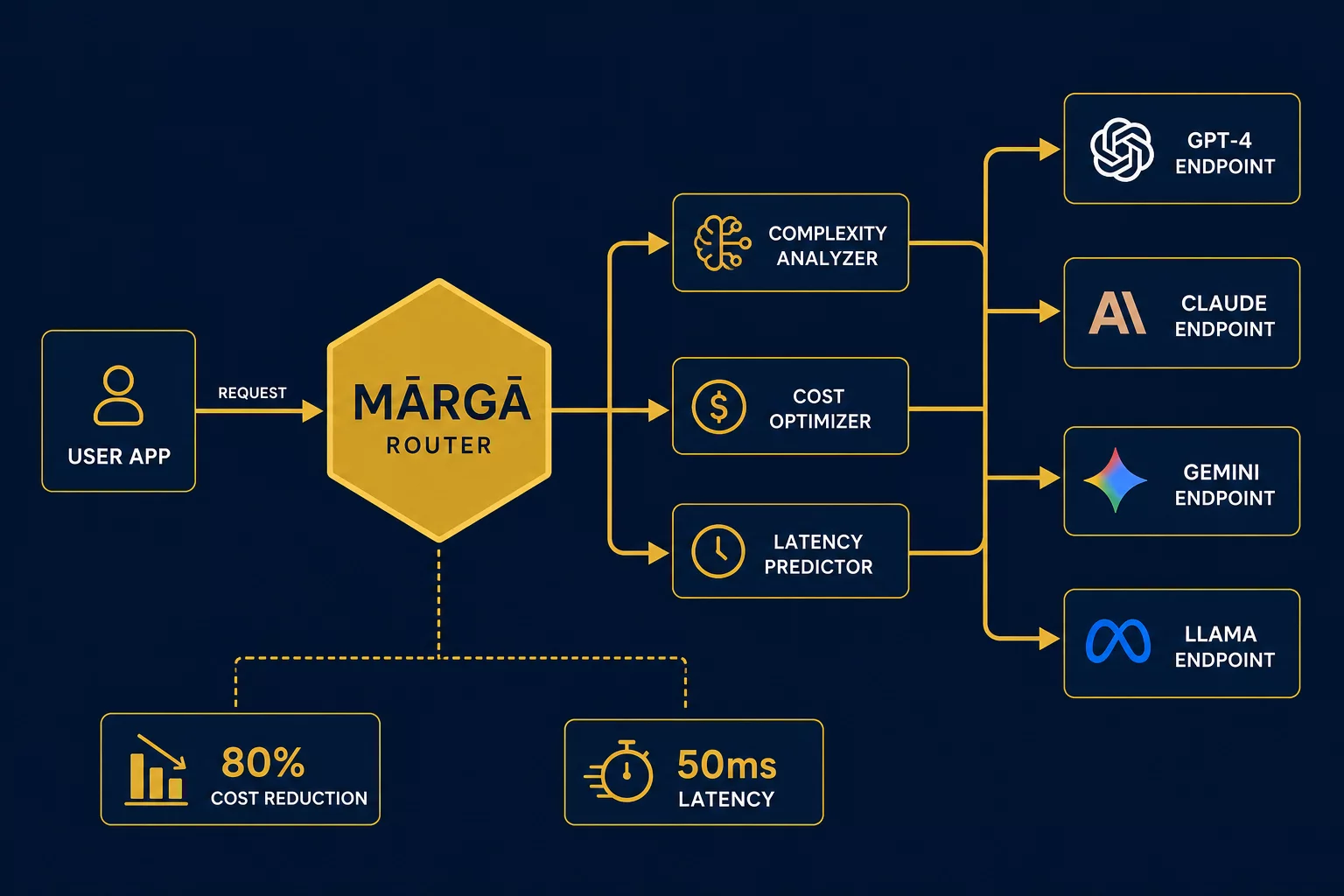
How MĀRGA Routes Requests
Like a hospital triage nurse — you don't send every patient to the head surgeon. MĀRGA classifies in under 10ms, then routes to the optimal model.
8ms Classification
The advisor runs on a tiny 4B model. Classification takes 5–8ms on modest hardware — imperceptible latency for massive cost savings.
3-Axis Routing
Every request is classified on task type, complexity, and latency requirements. Three dimensions are enough — more adds noise.
60–80% Cost Reduction
Most agent workloads don't need frontier models. MĀRGA routes 60–80% of requests to cheaper tiers without sacrificing output quality.
Self-Improving
Routing decisions feed back into the advisor. Over time, MĀRGA learns your workload patterns and gets more accurate at classification.
Model Agnostic
Works with any LLM provider — OpenAI, Anthropic, Google, local Ollama models. Swap models without changing application code.
Distributed Caching
Redis-powered distributed cache layer with intelligent prompt deduplication. Sub-millisecond cache lookups, cross-node consistency, and automatic TTL management — at 1M+ requests/day, the difference between 20% and 60% cache hits is the difference between profit and loss.
From $12K/mo to $2.4K/mo — Without Changing a Line of Code
A real-world stress test on commodity hardware demonstrates that MĀRGA handles production workloads with sub-millisecond overhead and extreme throughput.
Every request → GPT-4
An AI-powered DevOps platform was sending all requests — from simple “what's the status?” queries to complex incident analysis — to a single frontier model. At 50K requests/day, costs were $12,000/month and climbing 40% month-over-month.
MĀRGA as a drop-in proxy
Changed one line: base_url = "marga.avyay.ai/v1". The advisor classified each request in 8ms, routing 72% to cheaper tiers. Zero application code changes. Zero quality degradation on the tasks that matter.
Stress Test Results — Apple M2 Max, 32GB RAM
| Concurrency | Throughput | p50 | p95 | p99 | Errors |
|---|---|---|---|---|---|
| 100 | 64,532 req/s | 1.3ms | 3.2ms | 4.2ms | 0 |
| 1,000 | 59,345 req/s | 15.2ms | 22.0ms | 26.1ms | 0 |
| 5,000 | 47,329 req/s | 87.2ms | 98.2ms | 102.9ms | 0 |
| 10,000 | 49,419 req/s | 66.1ms | — | 125.0ms | 0 |
Zero errors at 10,000 concurrent connections. Rate limiter accuracy: 100% (120/120 exact). Cache hit rate: 99.8%.

OpenAI-Compatible API. Change the URL, Keep Your Code.
MĀRGA speaks the OpenAI Chat Completions protocol. Any SDK or tool that works with OpenAI works with MĀRGA — just swap the base URL.
from openai import OpenAI
# Drop-in replacement — just change the base URL
client = OpenAI(
base_url="https://marga.avyay.ai/v1",
api_key="your-marga-key"
)
response = client.chat.completions.create(
model="auto", # MĀRGA picks the optimal model
messages=[
{"role": "user", "content": "Summarize this incident report..."}
]
)
print(response.choices[0].message.content)Pay for What You Route
Start free, scale when ready. No hidden fees, no per-seat pricing. You only pay for routing — model costs are passed through at cost.
- ✓1,000 routed requests / day
- ✓2 model tiers (Tier 0 + Tier 1)
- ✓OpenAI-compatible API
- ✓Basic analytics dashboard
- ✓Community support
- ✓Unlimited routed requests
- ✓All 4 model tiers + custom tiers
- ✓Self-host or managed deployment
- ✓SSO / SAML authentication
- ✓Custom model integrations
- ✓SLA guarantees (99.99%)
- ✓Dedicated support + Slack channel
- ✓On-prem deployment option
All plans include model cost pass-through at provider rates — no markup. MĀRGA only charges for routing intelligence, not the underlying model usage.
Get Early Access to MĀRGA
Join our alpha program. Limited spots — we'll review applications and send API keys to approved users.