
Everyone building with LLMs eventually hits the same wall: the model doesn't know your data.
The standard fix is RAG — Retrieval-Augmented Generation. Chunk your documents, embed them into vectors, store them in a vector database, and retrieve the top-k most similar chunks when a user asks a question. The LLM reads those chunks and generates an answer grounded in your data.
It works. Sort of. For demos and prototypes, it's magic. For production enterprise systems with thousands of documents across dozens of departments? It falls apart in ways that are hard to debug and expensive to fix.
The failure mode isn't obvious. The system returns answers. They sound confident. They cite sources. They're just wrongoften enough that nobody trusts them — and “often enough” is lower than you think. In enterprise settings, a 90% accuracy rate means one in ten answers is wrong. That's not a search engine. That's a liability.
Here's the deeper problem: vector similarity is a proxy for relevance, not a measure of it.And at enterprise scale, the gap between “similar” and “relevant” becomes a canyon.
The Five Ways Vanilla RAG Breaks
After building retrieval systems for enterprise data — internal wikis, Slack archives, support tickets, financial reports, and engineering runbooks — we've seen the same failure patterns repeat across every deployment.
1. The Chunk Boundary Problem
RAG pipelines chunk documents into 500-1000 token segments. This is a practical necessity — embedding models have context limits, and smaller chunks produce more precise similarity matches.
But information doesn't respect chunk boundaries. A policy document might define a term in paragraph 3 and use it in paragraph 47. A technical spec might describe the architecture in section 2 and the failure modes in section 8. When you chunk these documents, you sever the connections between related concepts.
Here's what this looks like in practice:
# What the user asks:
"What happens if our payment processor goes down?"
# What vanilla RAG retrieves (top-3 chunks):
1. "...payment processor integration handles
retry logic with exponential backoff..."
(from: architecture.md, chunk 14)
2. "...downtime procedures for critical services
include escalation to on-call..."
(from: incident-response.md, chunk 7)
3. "...payment processing fees are 2.9% + $0.30
per transaction..."
(from: pricing.md, chunk 3)
# What the LLM generates:
"If the payment processor goes down, the system
uses retry logic with exponential backoff. The
fee is 2.9% + $0.30 per transaction."
# What the actual answer requires:
# - Architecture doc: retry logic + circuit breaker
# - Incident response: escalation + SLA requirements
# - Business continuity: fallback processor activation
# - Customer comms: payment failure notification template
# - Finance: revenue impact calculation methodology
# None of these connections exist in the vector space.The correct answer requires synthesizing information across five documents and understanding the relationships between them. Vector similarity finds documents that mention similar words. It doesn't find documents that are logically connected to the question.
2. The Freshness Problem
Enterprise data changes constantly. Policies update. People leave. Products evolve. Processes get revised.
Most RAG pipelines treat all chunks as equally valid. A product description from 2023 has the same weight as one from 2026. A policy that was superseded last month sits next to its replacement. When the user asks “what's our refund policy?”, they might get the version from three policy revisions ago — and the system won't flag the discrepancy.
This isn't a bug in any particular vector database. It's a fundamental limitation of treating documents as bags of embeddings. Embeddings capture semantic meaning. They don't capture temporal validity, authority, or supersession relationships.
3. The Authority Problem
Not all documents are created equal. A CEO's strategy memo carries different weight than a junior analyst's draft. An approved policy document is more authoritative than a Slack message discussing potential changes to that policy.
Vector similarity doesn't encode authority. When you search for “Q3 revenue targets,” you might get the CFO's board presentation, a sales rep's optimistic forecast in Slack, and a brainstorming doc with preliminary numbers — all with similar embeddings, all presented as equally valid context.
In enterprise settings, this isn't an edge case. It's the primary failure mode. The system retrieves plausible-sounding information from low-authority sources, and the LLM weaves it into a confident-sounding answer that's based on someone's speculative Slack message.
4. The Multi-Hop Reasoning Problem
Many enterprise questions require following a chain of relationships:
- “Which customers are affected by the API deprecation?” requires: knowing which API → which features use it → which customers use those features → which have active contracts.
- “Who should approve this expense?” requires: knowing the amount → the department policy → the approval hierarchy → current delegation rules → who's on vacation.
- “What's our exposure if Vendor X fails?” requires: which services depend on Vendor X → which products use those services → which customers use those products → what SLAs we have → what the financial impact would be.
Each hop in the chain involves a different document, a different data source, and a different type of relationship. Vector similarity retrieves documents that are individually similar to the query. It doesn't traverse relationship chains between entities.
Microsoft's GraphRAG paper (Edge et al., 2024) demonstrated this quantitatively: on global sensemaking queries — questions that require synthesizing information across an entire corpus — knowledge-graph-based retrieval outperformed vector-only retrieval by 40-80% on comprehensiveness and diversity metrics.
5. The Contradiction Problem
Large enterprises have contradictory information everywhere. The marketing site says one thing. The internal wiki says another. An old Confluence page says a third thing. A Slack thread from last month reveals that all three are wrong and the actual policy is something else entirely.
Vector RAG retrieves all of these. The LLM has no way to determine which source is authoritative, current, or correct. It usually picks the one that sounds most confident — which is often the marketing copy, not the actual policy.
What Knowledge Graphs Fix
A knowledge graph doesn't replace vector search. It adds a structural layer that addresses exactly the five failures above.
In a knowledge graph, information is stored as entities and relationships, not just chunks of text:
[Payment Processor] --depends_on--> [Stripe API]
[Stripe API] --used_by--> [Checkout Service]
[Checkout Service] --serves--> [Enterprise Plan Customers]
[Enterprise Plan] --has_sla--> [99.95% uptime]
[Payment Failure] --triggers--> [Incident Response Playbook]
[Incident Response Playbook] --escalates_to--> [On-Call Engineer]
[On-Call Engineer] --current_rotation--> [Alice Chen]When someone asks “what happens if our payment processor goes down?”, the system doesn't just find similar chunks. It traverses the graph:
- Payment processor → depends on Stripe API
- Stripe API → used by Checkout Service
- Checkout Service → serves Enterprise Plan Customers (with 99.95% SLA)
- Payment failure → triggers Incident Response Playbook
- Playbook → escalates to current on-call (Alice Chen)
This is the difference between searching and reasoning. The graph encodes the relationships that chunks lose.
How Each Failure Gets Fixed
Chunk boundaries→ Entities and relationships span across documents. The knowledge graph connects the architecture doc's retry logic to the incident response doc's escalation path because both reference the same entity (Payment Processor).
Freshness → Every entity and relationship carries a timestamp, a version, and a source. When the refund policy updates, the old version is marked superseded, not deleted. The system knows which version is current.
Authority→ Sources have trust scores. The CEO's board deck gets a higher trust score than a Slack brainstorm. When contradictions exist, the system surfaces the highest-authority source and flags the conflict.
Multi-hop reasoning → Graph traversal is literally what graphs do. Following a chain of relationships from API deprecation → affected features → affected customers → active contracts is a straightforward query, not a multi-retrieval prayer.
Contradictions → Because every fact is attributed to a source with a trust score and timestamp, contradictions are detected, not hidden. The system can tell you “the marketing site says X, but the approved policy says Y, and Y is more recent and from a higher-authority source.”
Building a Knowledge Graph That Actually Works
Most “knowledge graph” implementations fail because they try to pre-define every entity type and relationship before ingesting any data. This is the enterprise ontology trap — you spend six months building a schema that's obsolete by the time you deploy it.
The approach that works is extraction-first: use LLMs to extract entities and relationships from your existing documents, then refine the schema based on what emerges.
Step 1: Entity Extraction
from typing import List, Dict
import json
EXTRACTION_PROMPT = """
Analyze this document and extract structured entities
and relationships.
For each entity, provide:
- name: canonical name
- type: person | team | system | process | policy |
document | metric | tool
- attributes: key-value pairs of important properties
For each relationship, provide:
- source: entity name
- target: entity name
- type: owns | depends_on | reports_to | serves |
triggers | supersedes | contradicts | references
- confidence: 0.0 to 1.0
- evidence: the exact text that supports this relationship
Document:
{document_text}
Source metadata:
- file: {filename}
- author: {author}
- last_modified: {modified_date}
- source_type: {source_type}
"""
def extract_entities(doc: dict, llm_client) -> dict:
"""Extract entities and relationships from a document."""
response = llm_client.complete(
EXTRACTION_PROMPT.format(
document_text=doc["content"],
filename=doc["filename"],
author=doc.get("author", "unknown"),
modified_date=doc.get("modified_date", "unknown"),
source_type=doc.get("source_type", "document"),
)
)
extracted = json.loads(response)
# Attach provenance to every entity
for entity in extracted["entities"]:
entity["source_doc"] = doc["filename"]
entity["source_author"] = doc.get("author")
entity["extracted_at"] = datetime.utcnow().isoformat()
entity["source_trust_score"] = compute_trust_score(doc)
return extracted
def compute_trust_score(doc: dict) -> float:
"""
Trust scoring based on source type, recency, and author.
Scale: 0.0 (untrusted) to 1.0 (authoritative).
"""
base_scores = {
"approved_policy": 0.95,
"board_presentation": 0.90,
"technical_spec": 0.85,
"wiki_page": 0.70,
"confluence_page": 0.65,
"email": 0.50,
"slack_message": 0.30,
"draft": 0.20,
}
score = base_scores.get(
doc.get("source_type"), 0.50
)
# Decay based on age
days_old = (datetime.utcnow() - doc["modified_date"]).days
if days_old > 365:
score *= 0.7
elif days_old > 180:
score *= 0.85
elif days_old > 90:
score *= 0.95
return round(score, 2)Step 2: Graph Construction with Deduplication
The extraction step produces raw entities from each document. Before loading them into the graph, you need to resolve duplicates. “Alice Chen,” “A. Chen,” and “alice@company.com” are the same person. “Payment Service,” “payment-service,” and “the checkout payment handler” are the same system.
def resolve_entities(entities: List[dict]) -> List[dict]:
"""
Merge duplicate entities using embedding similarity
+ rule-based matching.
"""
resolved = []
for entity in entities:
match = find_existing_match(entity, resolved)
if match:
# Merge: keep highest-trust-score attributes,
# union all source docs
merge_entities(match, entity)
else:
resolved.append(entity)
return resolved
def find_existing_match(
new_entity: dict,
existing: List[dict]
) -> dict | None:
"""
Match by: exact name, normalized name, email,
or embedding similarity > 0.92.
"""
normalized_name = normalize(new_entity["name"])
for entity in existing:
if entity["type"] != new_entity["type"]:
continue
# Exact or normalized name match
if normalize(entity["name"]) == normalized_name:
return entity
# Email-based match for persons
if (entity["type"] == "person" and
entity.get("email") == new_entity.get("email")):
return entity
# Embedding similarity for fuzzy matches
sim = cosine_similarity(
embed(entity["name"]),
embed(new_entity["name"])
)
if sim > 0.92:
return entity
return NoneStep 3: Trust-Scored Retrieval
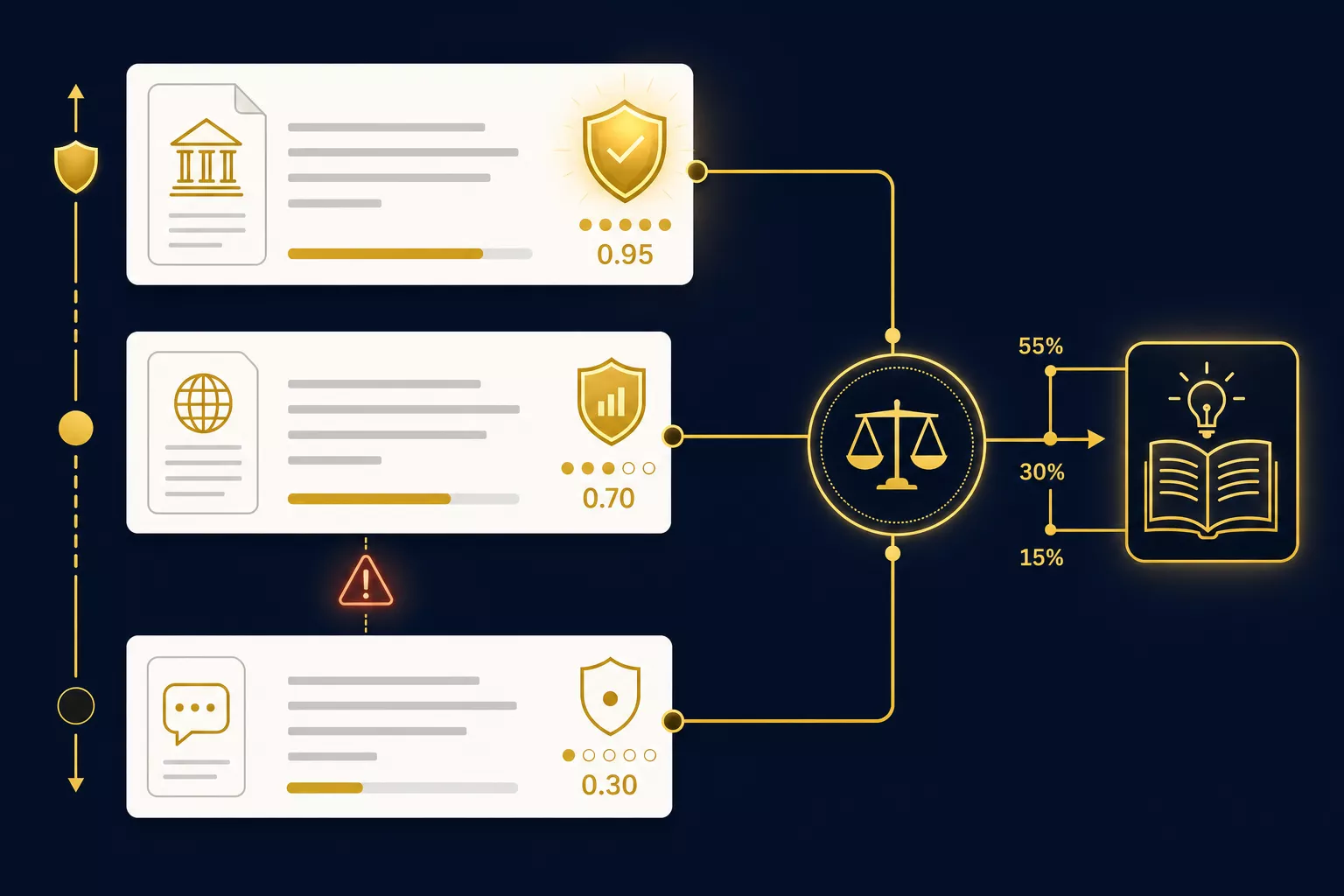
This is where knowledge graphs fundamentally change how retrieval works. Instead of “find the 5 most similar chunks,” the query becomes “traverse the graph from the query entities, weighted by trust scores and recency.”
def graph_retrieve(
query: str,
graph,
llm_client,
max_hops: int = 3,
min_trust: float = 0.5,
) -> dict:
"""
Hybrid retrieval: vector search for entry points,
graph traversal for connected context.
"""
# Step 1: Extract query entities
query_entities = llm_client.extract_entities(query)
# Step 2: Find entry points via vector similarity
vector_matches = vector_store.search(
query, top_k=10, min_score=0.75,
)
# Step 3: Map matches to graph nodes
entry_nodes = []
for match in vector_matches:
nodes = graph.find_nodes_by_source(
match.document_id
)
entry_nodes.extend(nodes)
# Step 4: Traverse graph from entry points
context = GraphContext()
for node in entry_nodes:
traverse(
graph, node, context,
hops_remaining=max_hops,
min_trust=min_trust,
)
# Step 5: Rank by trust score * relevance * recency
context.rank()
# Step 6: Build structured context for LLM
return {
"entities": context.top_entities(20),
"relationships": context.top_relationships(30),
"sources": context.sources_with_trust_scores(),
"contradictions": context.detected_contradictions(),
"confidence": context.overall_confidence(),
}What Most People Miss
Knowledge Graphs Don't Require Perfect Extraction
The biggest objection to knowledge graphs is “but entity extraction isn't perfect.” This is true. LLM-based extraction has roughly 85-92% precision depending on the domain and document complexity.
But here's what people miss: vector search isn't perfect either. It has roughly 70-80% relevance precision on enterprise data (measured as “percentage of retrieved chunks that a human would consider relevant to the query”). Knowledge graph retrieval, even with imperfect extraction, typically achieves 85-95% relevance precision because the graph structure constrains retrieval to logically connected information rather than semantically similar text.
The graph also has a self-healing property: when you add more documents that reference the same entities, extraction errors get corrected through entity resolution. If document A incorrectly classifies “Alice Chen” as a “system” but documents B, C, and D correctly classify her as a “person,” the resolution algorithm corrects the error.
Trust Scoring Changes Everything
Most RAG discussions focus on retrieval accuracy. But in enterprise settings, the harder problem is trust: when the system returns an answer, how confident should the user be?
Trust scoring — attaching a provenance and authority measure to every piece of information — transforms RAG from a search tool into a decision-support system. The difference:
Without trust scoring:
“Our refund policy allows returns within 30 days.”
(Source: some document)
With trust scoring:
“Our refund policy allows returns within 30 days.”
Source: Customer Service Policy v4.2 (approved by Legal, Feb 2026) — Trust: 0.95
Note: Contradicts Marketing FAQ page (Trust: 0.40) which states “14 days” — likely outdated
Confidence: High (single authoritative source, recently updated)
The second answer doesn't just tell you the policy. It tells you how much to trust the answer and why. That's the difference between a search engine and a knowledge system.
You Don't Need a Graph Database
This surprises people. You can build an effective knowledge graph using PostgreSQL with JSONB columns and a self-referencing edges table. For most enterprise deployments under 10 million entities, a relational database with proper indexing outperforms dedicated graph databases on the query patterns that RAG actually needs (2-3 hop traversals with trust score filtering).
-- Entities table
CREATE TABLE kg_entities (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
name TEXT NOT NULL,
entity_type TEXT NOT NULL,
attributes JSONB DEFAULT '{}',
trust_score NUMERIC(3,2) DEFAULT 0.50,
source_docs TEXT[] DEFAULT '{}',
created_at TIMESTAMPTZ DEFAULT now(),
updated_at TIMESTAMPTZ DEFAULT now(),
embedding vector(1536)
);
-- Relationships table
CREATE TABLE kg_edges (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
source_id UUID REFERENCES kg_entities(id),
target_id UUID REFERENCES kg_entities(id),
edge_type TEXT NOT NULL,
confidence NUMERIC(3,2) DEFAULT 0.80,
evidence TEXT,
source_doc TEXT,
trust_score NUMERIC(3,2) DEFAULT 0.50,
created_at TIMESTAMPTZ DEFAULT now()
);
-- 2-hop traversal with trust filtering
-- ~5ms on 1M entities with proper indexes
SELECT DISTINCT
e2.name AS connected_entity,
e2.entity_type,
r1.edge_type AS hop1_relation,
r2.edge_type AS hop2_relation,
LEAST(r1.trust_score, r2.trust_score) AS min_trust
FROM kg_entities e0
JOIN kg_edges r1 ON e0.id = r1.source_id
JOIN kg_entities e1 ON r1.target_id = e1.id
JOIN kg_edges r2 ON e1.id = r2.source_id
JOIN kg_entities e2 ON r2.target_id = e2.id
WHERE e0.name = 'Payment Processor'
AND LEAST(r1.trust_score, r2.trust_score) >= 0.5
ORDER BY min_trust DESC
LIMIT 30;We use this exact pattern in Avyay's Second Brain. It handles 25,000+ entities across multiple enterprise deployments with p95 query latency under 12ms.
Common Mistakes and Tradeoffs
Mistake 1: Trying to Build the Complete Ontology First
The enterprise instinct is to hire a consultant, spend three months defining an ontology, then build the system to match. This fails every time because the ontology is based on how people thinkinformation is structured, not how it actually is. By the time the ontology is “ready,” the organization has changed.
Instead:Start with a minimal type system (person, team, system, process, document) and let the LLM extraction surface entity types you didn't anticipate. Refine the schema iteratively.
Mistake 2: Skipping Vector Search Entirely
Knowledge graphs are not a replacement for vector search. They're a complement. Vector search is still the fastest way to find entry points — documents and entities that are semantically relevant to a query. The graph takes over for relationship traversal and trust-scored ranking.
The architecture that works: vector search for breadth, graph traversal for depth.
Mistake 3: Not Handling Contradictions
The natural instinct is to resolve contradictions during ingestion — pick the “right” answer and discard the others. This is almost always wrong. Contradictions are information. They tell you that your organization has conflicting policies, outdated documentation, or misaligned teams.
Instead: Store all versions, tag them with trust scores and timestamps, and surface contradictions to users. Let humans decide which version is authoritative. The system's job is to detect contradictions, not resolve them.
Mistake 4: Overcomplicating the Graph Schema
Every entity doesn't need 50 relationship types. In practice, 8-10 relationship types cover 90% of enterprise knowledge:
| Relationship | What It Captures |
|---|---|
owns | Team/person → system/process/document |
depends_on | System → system, process → process |
reports_to | Person → person hierarchy |
serves | System/service → customer/user group |
triggers | Event → process/playbook |
supersedes | New document/policy → old version |
contradicts | Conflicting facts between sources |
references | Generic association |
Start with these. Add more only when you encounter a real query that can't be answered with existing types.
Tradeoff: Ingestion Cost vs Query Quality
Building a knowledge graph requires LLM calls during ingestion — roughly one call per 2,000 tokens of source material for entity extraction. At current API prices, ingesting 10,000 documents costs approximately $15-40 depending on the model (Gemini Flash or GPT-4o-mini work well for extraction).
This is a one-time cost per document, amortized across every future query. Compare it to the cost of a single wrong answer reaching a customer, and the economics are trivial.
For ongoing ingestion, the cost is proportional to the rate of document creation. Most enterprises create 50-200 documents per day across all systems. At $0.003 per extraction, that's under $1/day for continuous knowledge graph maintenance.
The Architecture: How It All Fits Together
Here's the complete system, from document ingestion to user query:
┌─────────────────────────────────────────────┐
│ Document Sources │
│ Confluence │ Slack │ Drive │ Jira │ Email │
└──────────────────┬──────────────────────────┘
▼
┌──────────────────────────────────────────────┐
│ Ingestion Pipeline │
│ ┌──────────┐ ┌───────────┐ ┌───────────┐ │
│ │ Chunk │→ │ Extract │→ │ Resolve │ │
│ │ & Embed │ │ Entities │ │ & Merge │ │
│ └──────────┘ └───────────┘ └───────────┘ │
└──────────┬──────────────┬────────────────────┘
▼ ▼
┌──────────────┐ ┌─────────────────┐
│ Vector Store │ │ Knowledge Graph │
│ (chunks + │ │ (entities + │
│ embeddings)│ │ relationships │
│ │ │ + trust scores│
│ │ │ + timestamps) │
└──────┬───────┘ └────────┬────────┘
│ │
▼ ▼
┌──────────────────────────────────────────────┐
│ Hybrid Retrieval Engine │
│ │
│ 1. Vector search → candidate chunks │
│ 2. Map chunks → graph entities │
│ 3. Graph traversal (2-3 hops) │
│ 4. Trust-score ranking │
│ 5. Contradiction detection │
│ 6. Structured context assembly │
└──────────────────────┬───────────────────────┘
▼
┌──────────────────────────────────────────────┐
│ LLM Generation │
│ │
│ Context: entities + relationships + trust │
│ Output: answer + sources + confidence │
│ Guardrail: flag low-confidence answers │
└──────────────────────────────────────────────┘The key insight: the graph doesn't replace any existing component. It adds a structural layer between your raw documents and your LLM. Every existing chunk, embedding, and vector search query continues to work. The graph makes them more precise by filtering, ranking, and connecting them through entity relationships.
Start Here
If you're evaluating whether a knowledge graph would improve your RAG pipeline, ask three questions:
- Do your users ask questions that span multiple documents? If yes, you need graph traversal, not just vector search.
- Does your organization have contradictory or outdated information? If yes, you need trust scoring and contradiction detection.
- Do your users need to follow chains of relationships? If yes, you need multi-hop graph queries.
If you answered yes to any of these — and in enterprise settings, it's almost always all three — vector search alone won't get you there.
- Avyay Second Brain — Knowledge graph + RAG engine with trust scoring, entity resolution, and contradiction detection built in
- Avyay MĀRGA — Intelligent LLM routing that pairs with Second Brain for cost-effective, accurate retrieval
- Contact us — We'll audit your current RAG pipeline and show you where graph-based retrieval would improve accuracy
Published on avyay.ai — Avyay builds enterprise AI that doesn't decay. Our Second Brain platform turns your enterprise documents into a living knowledge graph with trust scoring, entity resolution, and multi-hop retrieval — so your AI answers questions with the confidence of someone who actually understands your business.